
提到 “数据治理”,很多人会联想到复杂术语与繁琐流程,觉得这是 IT 专家的专属领域。但实际上,数据治理的核心逻辑,和 “整理衣柜”“管理照片库” 高度相似 —— 都是通过 “建规则、优质量、便取用”,让 “资产”(衣物、照片、数据)发挥最大价值。今天我们从生活场景切入,用 “整理衣柜” 拆解数据治理,结合 “家庭照片库” 案例,带你轻松读懂核心概念。
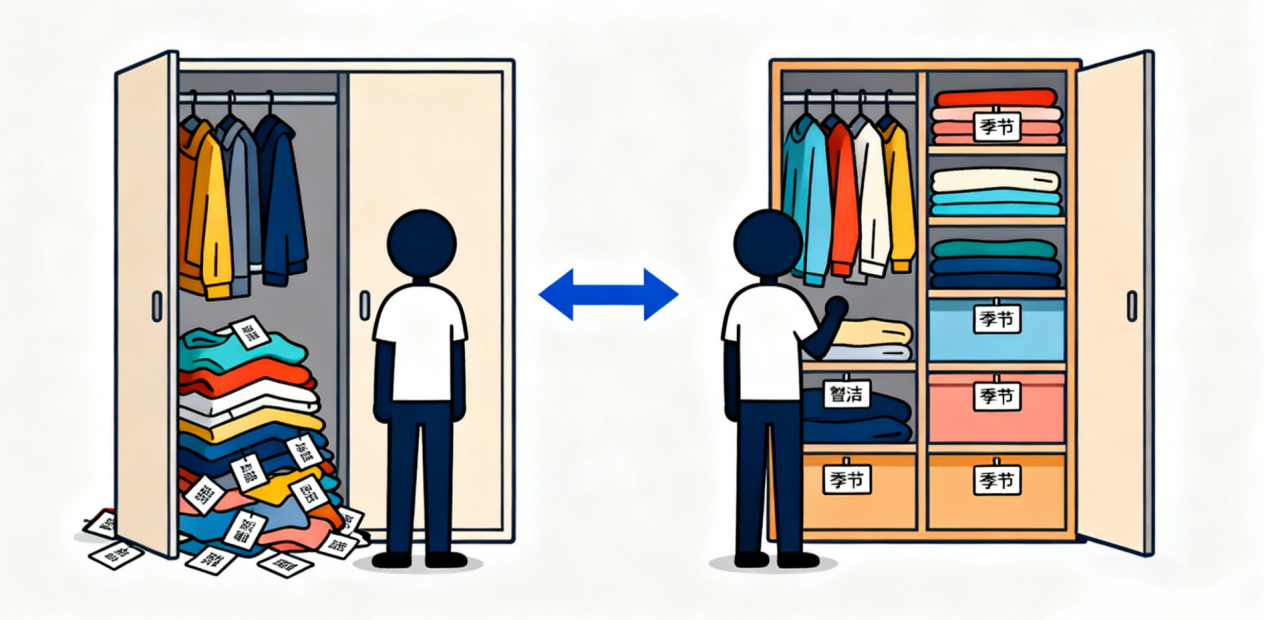
一、数据治理:给 “数据资产” 做 “收纳管理”
先想一个问题:为什么要整理衣柜?若衣物随意堆放,冬装与夏装混杂、袜子难配对、新衣被压箱底,不仅穿时翻找耗时,还可能重复购买或因存放不当浪费。
数据治理的初衷与此一致。企业数字化中,客户信息、订单记录等海量数据若不管理,会出现 “数据混乱”(同一客户姓名不一致)、“数据浪费”(重复数据占空间)、“数据失效”(过时价格误导决策)等问题。
简单说,数据治理是企业对 “数据资产” 的系统性管理,通过建立规则(数据标准)、优化状态(数据质量)、明确权责(数据归属),让数据从 “杂乱碎片” 变成 “决策依据”。
二、核心概念拆解:用 “衣柜逻辑” 懂数据治理
1. 数据标准 = 衣柜的 “分类标签”
整理衣柜第一步通常是分类:按季节分(春夏秋冬装)、按用途分(通勤、休闲、运动装),甚至给抽屉贴 “内衣”“袜子” 标签。这些 “分类规则” 就是衣柜管理的 “标准”。
数据标准的作用完全相同 ——给数据定统一的 “分类规则” 和 “描述规范”,让每份数据有明确归属与定义。
比如企业客户数据的 “数据标准” 可能包括:
客户姓名:需 “姓 + 名” 完整格式,禁用昵称(“张三” 不写成 “老张”);
客户手机号:11 位纯数字,无空格或括号(“13600138000” 不写成 “136 0013 8000”);
客户地址:按 “省 + 市 + 区 + 详细地址” 填写(“北京市朝阳区建国路 88 号” 不简写为 “建国路 88 号”)。
这些标准像衣柜标签,确保不同部门录入的数据 “格式统一、含义清晰”,避免混乱。
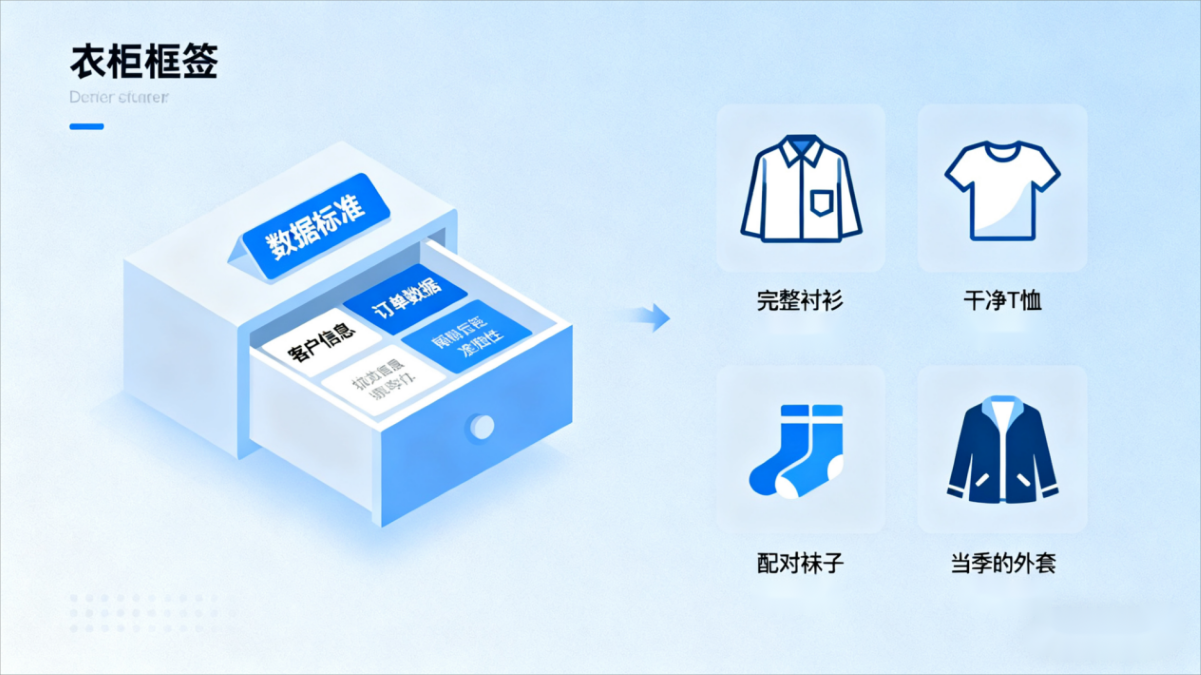
2. 数据质量 = 衣物的 “整洁度与可用性”
整理衣柜时,我们会熨平褶皱衣物、清洗脏衣、淘汰破损件、收纳过季衣 —— 目的是让衣物 “整洁、可用”。
数据质量的核心也是让数据 “能用、好用”,对应衣物状态,可拆解为四个维度:
完整性:数据无缺失,如客户数据中 “姓名 + 手机号” 缺一不可,否则无法联系客户;
准确性:数据真实正确,如订单金额误写 “10000 元”(实际 1000 元),会导致财务核算错误;
一致性:数据前后统一,如同一客户在 CRM 系统手机号为 “13800138000”,在订单系统却为 “13900139000”,会造成信息冲突;
时效性:数据不过时,如产品价格沿用去年旧价(今年已调价),会误导销售定价。
简言之,数据质量目标是 “完整、准确、一致、及时”,只有这样,数据才能支撑业务决策。
三、生活案例:家庭照片库的 “数据治理”
很多家庭面临照片库困扰:手机、电脑、U 盘中存数千张照片,找 “2023 年春节聚餐照” 需翻半天;重复存储占内存;默认命名(“IMG_1234.jpg”)让照片内容难辨识。这些问题与企业数据治理痛点一致,解决方法就是 “生活版数据治理”。
1. 照片库的 “数据标准”:命名规范
让照片库有序,第一步是定 “命名规范” —— 这就是照片库的 “数据标准”。可采用 “时间 + 场景 + 人物 + 备注” 规则,例如:
“20250122_春节聚餐_全家_奶奶家”;
“20250601_儿童节_小明_游乐园”;
“20251001_国庆旅行_爸妈_张家界”。
有了标准,谁存照片都知道如何命名;找照片时,搜 “2025 春节” 就能快速定位相关内容,和企业定 “客户数据标准” 逻辑一致。
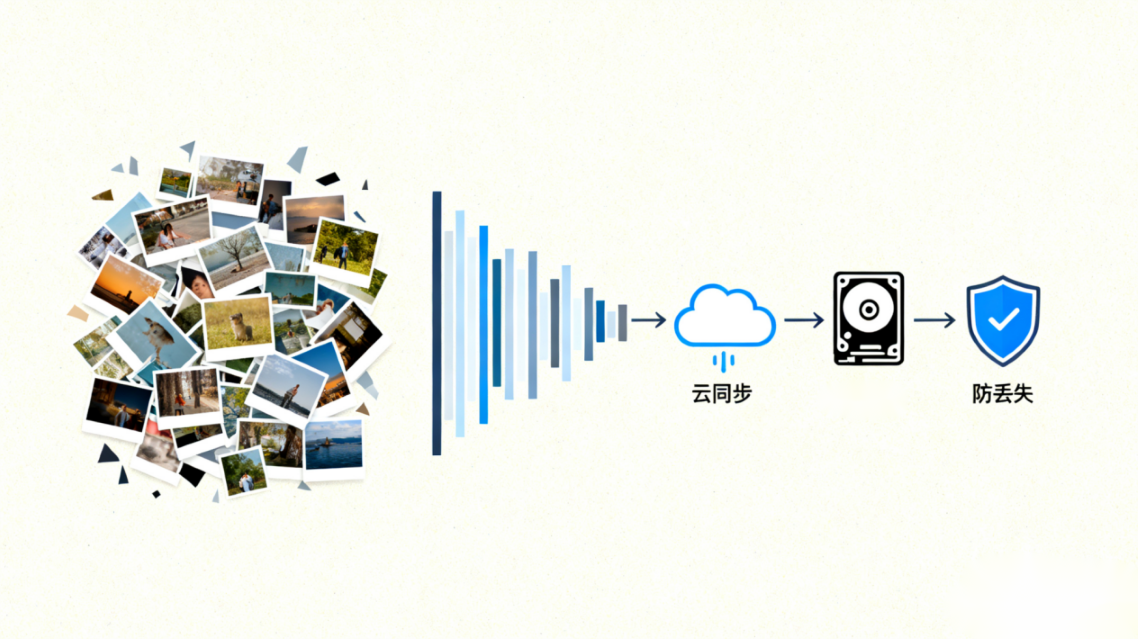
2. 照片库的 “数据质量”:备份与筛选
命名规范之外,需保证照片 “能用、不丢失”,核心动作是 “备份” 与 “筛选”:
备份策略:手机照片自动同步云端(百度云、腾讯云),每月将家庭聚会、孩子成长等重要照片拷贝到电脑硬盘,双重保险防丢失,类似企业核心数据 “多地备份”;
筛选优化:每季度整理照片,删重复图(同一角度留最清晰张)、无效图(黑图、模糊废片),给未命名照片补全名称,像企业清理 “重复数据”“无效数据”,保持照片库精简可用。
通过 “命名规范 + 备份筛选”,杂乱照片库变有序,这和企业数据治理逻辑相通,只是将 “照片” 换成 “客户 / 订单数据”。
四、企业数据治理:先做 “小而实” 的管理
数据治理不是 “技术难题”,而是基于规则与习惯的 “管理工作”。企业无需一开始搭复杂系统,可从两步入手:
先定 “小标准”:不从所有数据切入,先聚焦核心业务数据(客户、订单数据),定简单命名规范与格式要求,像整理衣柜先给 “常穿通勤装” 分类;
先抓 “高质量”:定期检查核心数据的完整性(无缺失)与准确性(无错误),像整理照片库删废片,先解决 “能用” 问题,再优化 “好用”。
整理衣柜让我们轻松找衣,管理照片库让我们随时忆美好,企业做好数据治理,能让业务人员快速获可靠数据、管理层做准确决策 —— 这就是数据治理的价值:让数据从 “负担” 变 “资产”,从 “混乱” 变 “有序”。
下次听到 “数据治理”,想想整理衣柜的场景 —— 其实你早掌握了核心逻辑。若想落地治理,可借助 DE 数据处理中台:作为专为中小企打造的低代码平台,DE 能一键抽取多源数据,通过可视化配置实现自动清洗、标准化转换,全流程串接至输出,无需技术背景也能快速建立规范的数据管理体系。


