存算分离
产品架构
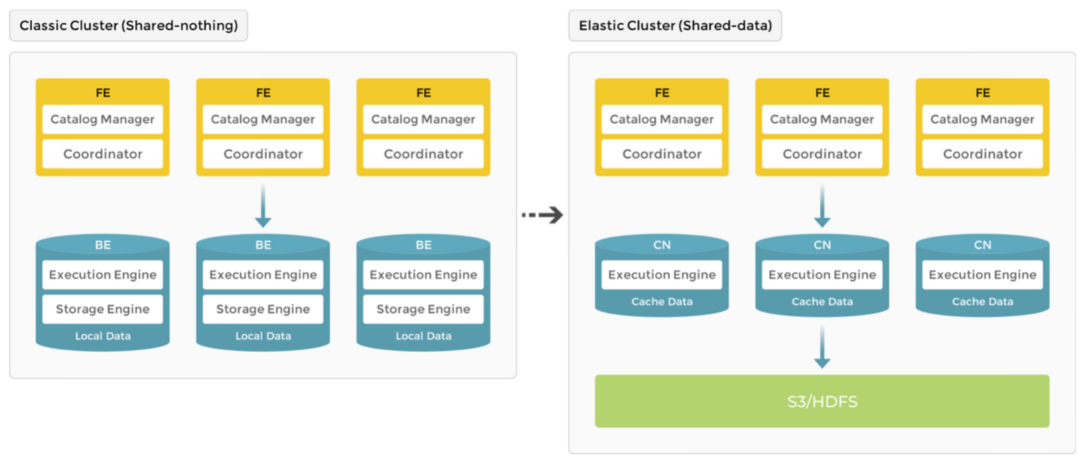
作为 MPP 数据库的典型代表,StarRocks 3.0 版本之前使用存算一体 (shared-nothing) 架构
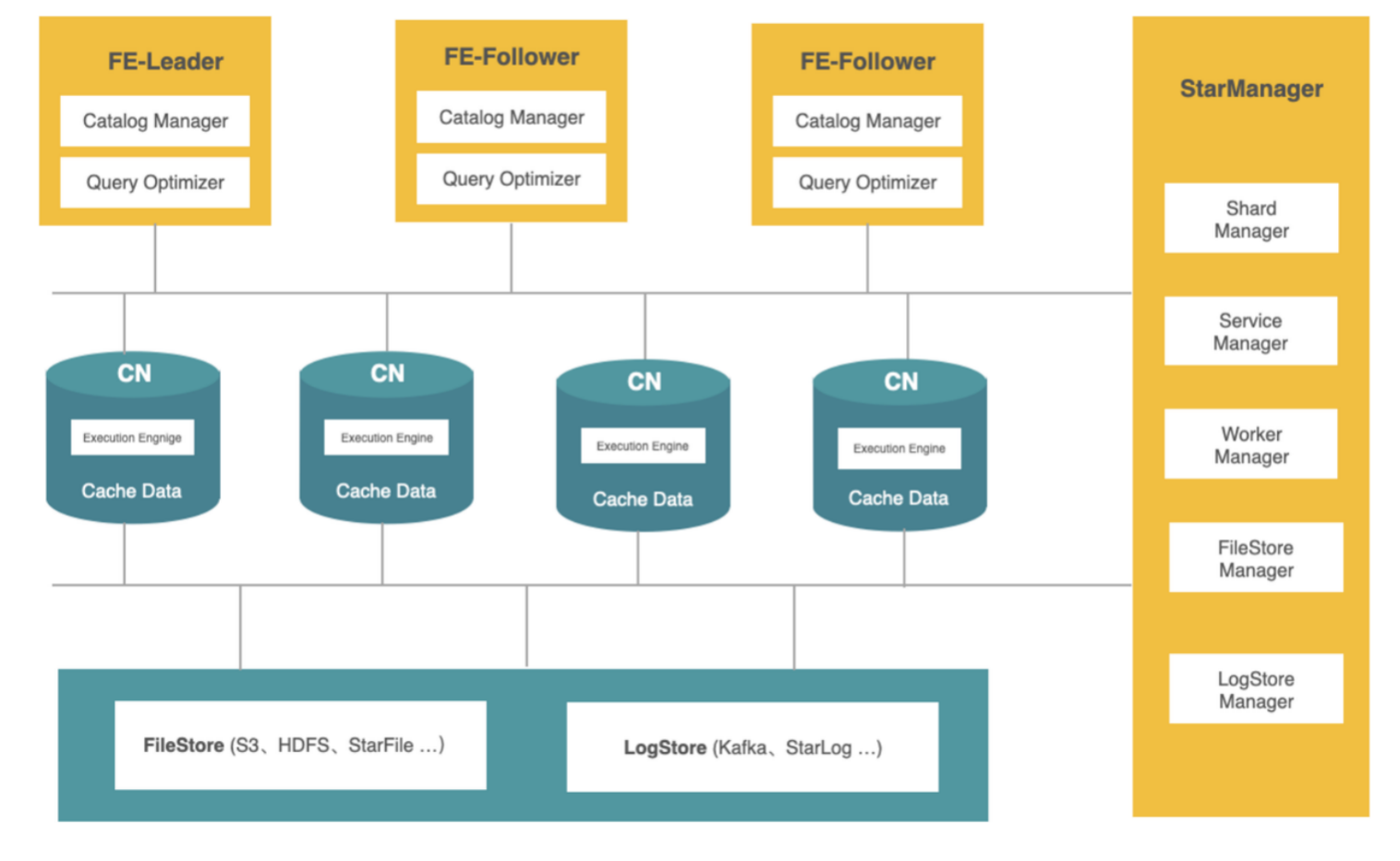
StarRocks 存算分离技术在现有存算一体架构的基础上,将计算和存储进行解耦。存算分离大大降低了数据存储成本和扩容成本,有助于实现资源隔离和计算资源的弹性伸缩
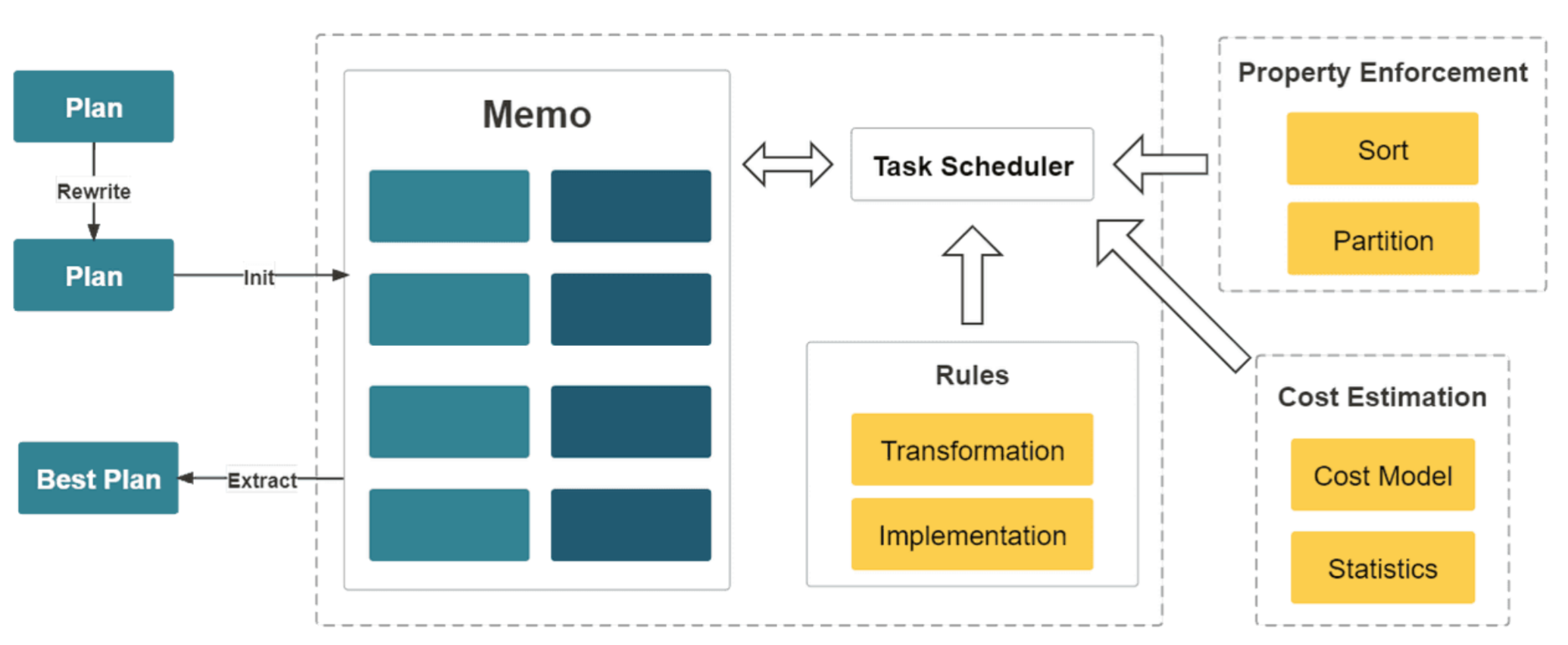
StarRocks 从零设计并实现了一款全新的,基于代价的优化器 CBO(Cost Based Optimizer),实现了公共表达式复用,相关子查询重写,Lateral Join,Join Reorder,Join 分布式执行策略选择,低基数字典优化等重要功能和优化
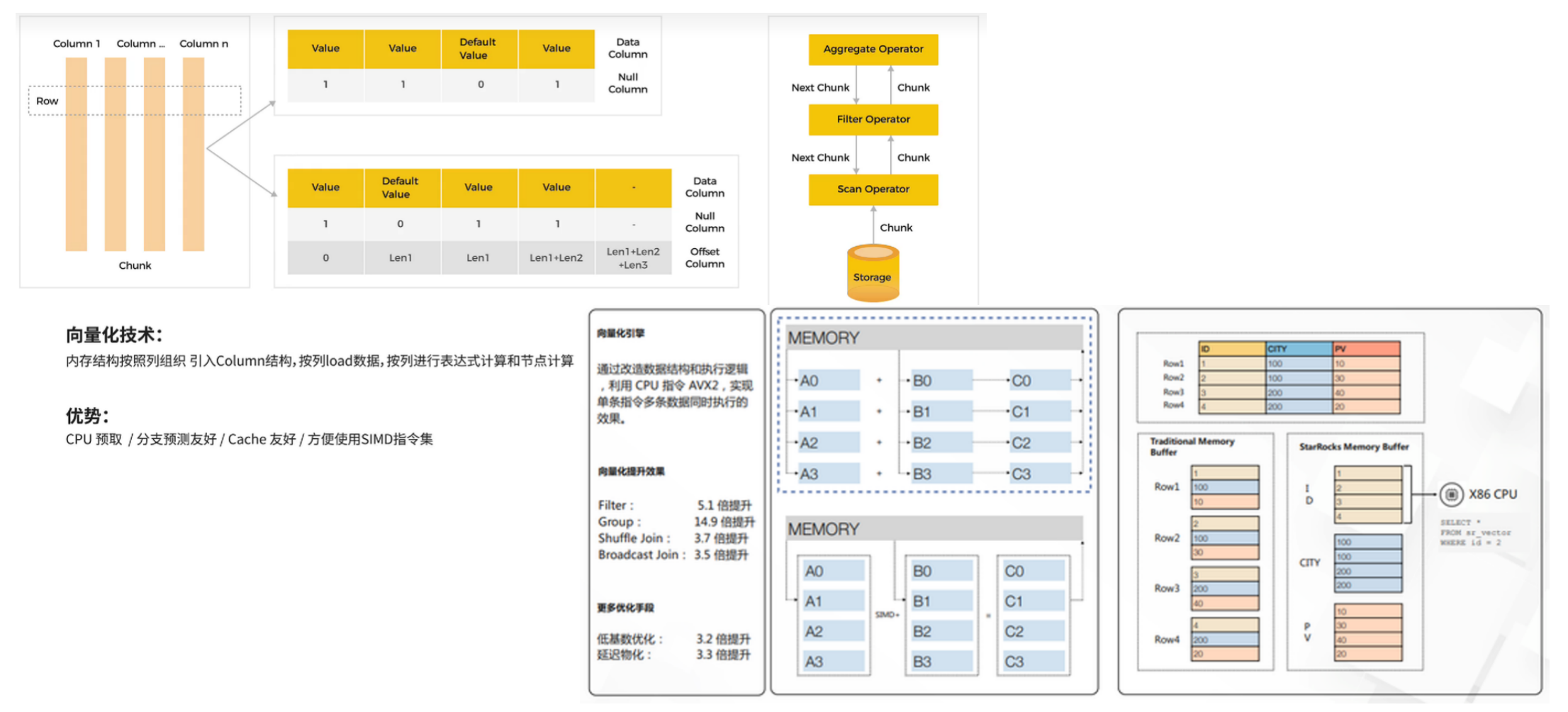
向量引擎
(Smartbi Insight)StarRocks的计算层全面采用了向量化技术,将所有算子、函数、扫描过滤和导入导出模块进行了系统性优化,实现亚秒级别多维分析能力
StarRocks 执⾏器的一个重大的特性就是向量化引擎。通过向量化引擎,可以极大程度的提高查询性能
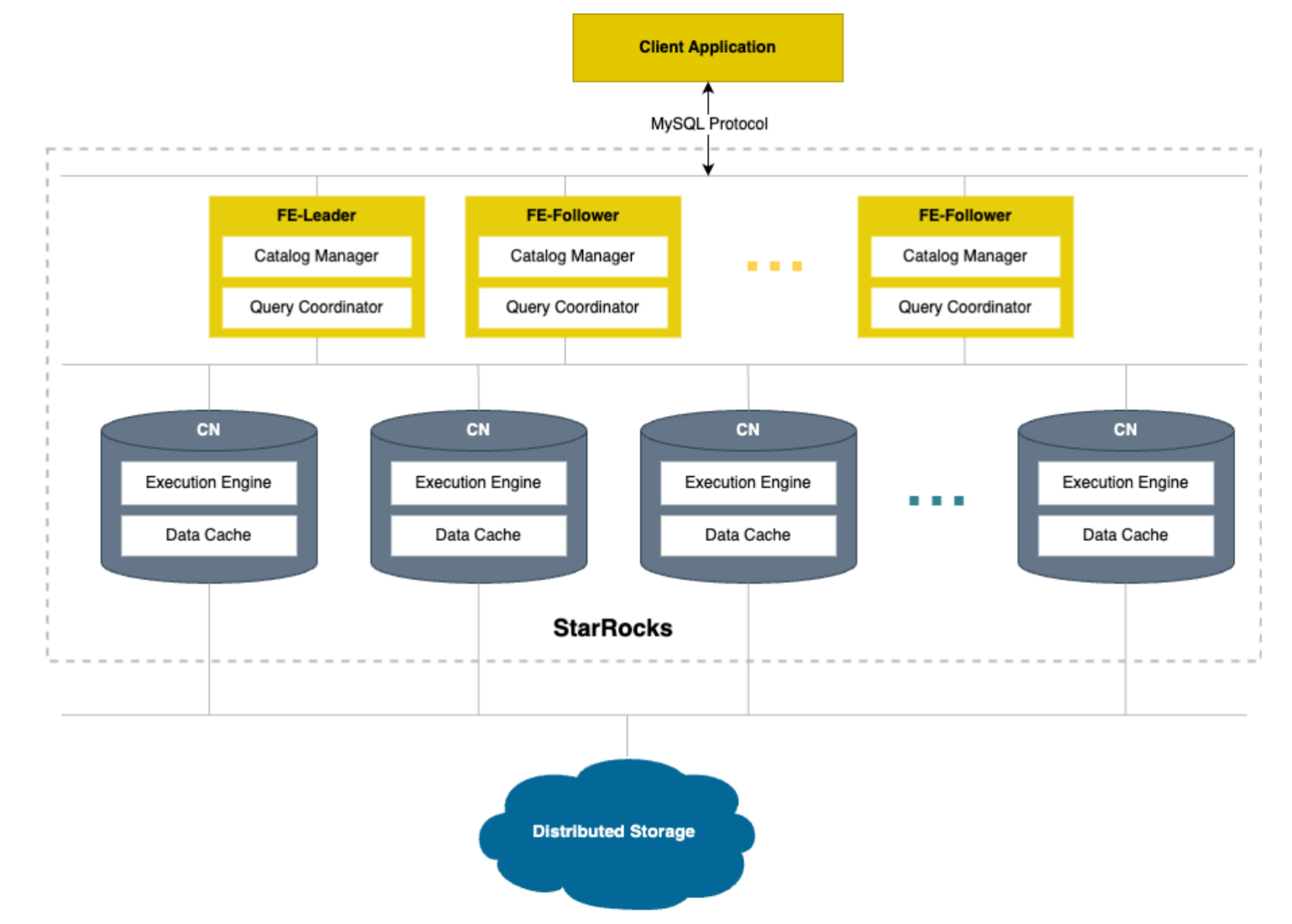
StarRocks 3.0 版本支持了全新的存算分离模式,实现了计算与存储的完全解耦、计算节点弹性扩缩容、高性能热数据缓存。存算分离模式下 StarRocks 具备灵活弹性、高性能、高可靠、低成本等特点
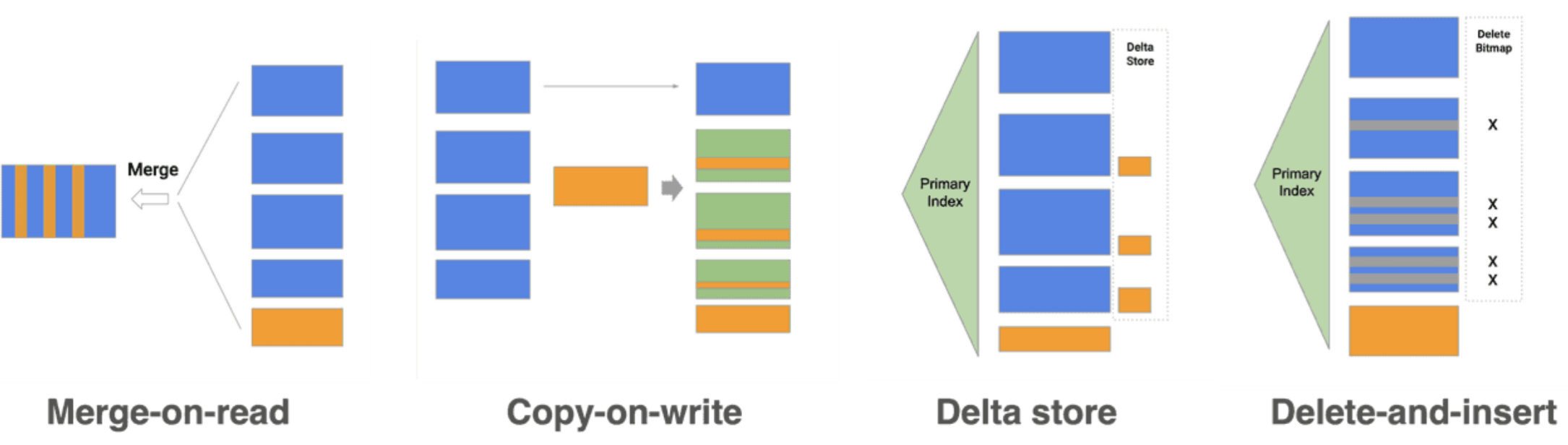
StarRocks 实现了列式存储引擎,数据以按列的方式进行存储,支持秒级导入延迟,提供准实时的服务能力
StarRocks 存储引擎不仅提供高效的 Partial Update 操作,也能高效处理 Upsert 类操作,保证查询极速性能
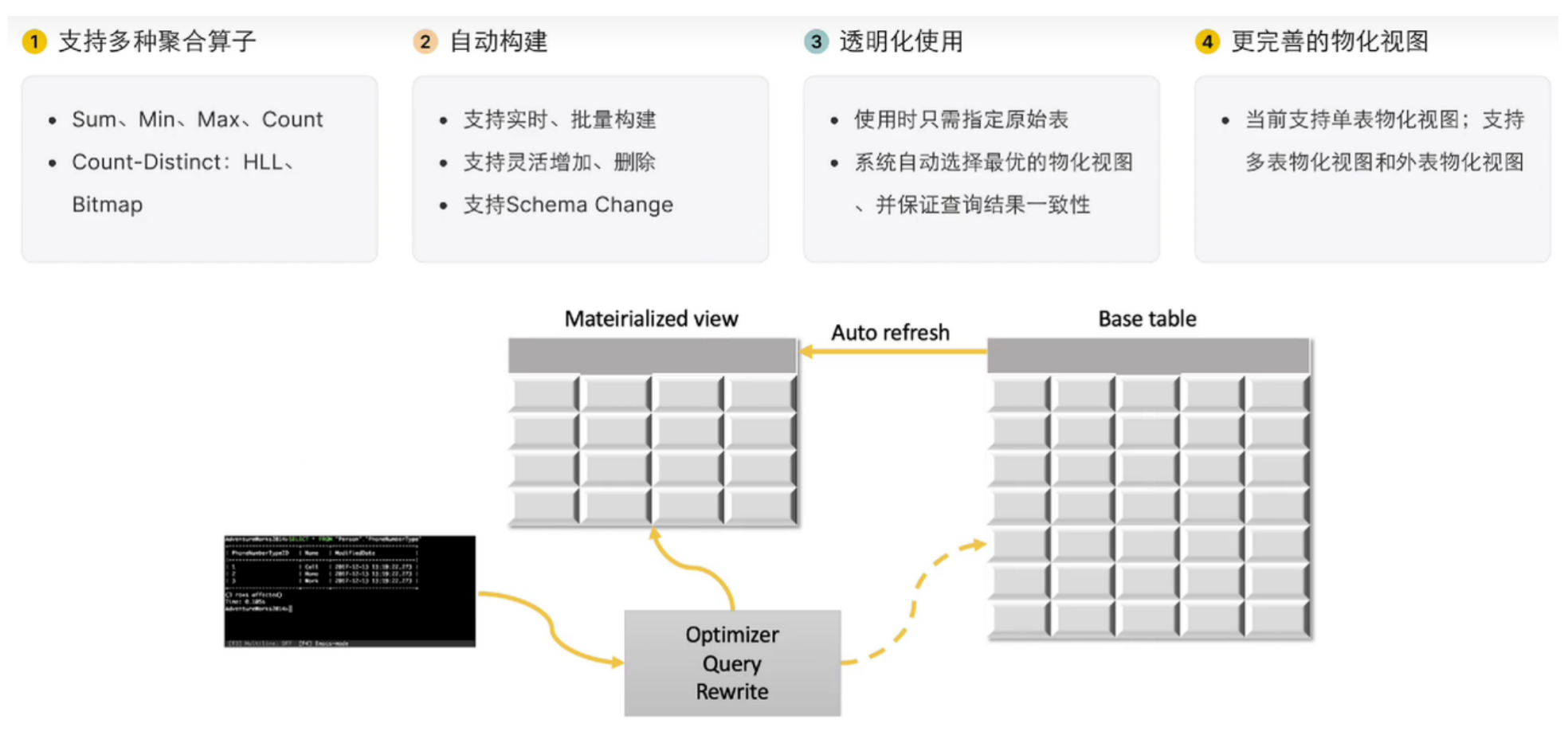
StarRocks 支持用户使用物化视图(materialized view)进行查询加速和数仓分层
StarRocks 的物化视图可以替代传统的 ETL 建模流程,用户无需在上游应用处做数据转换,可以在使用物化视图时完成数据转换,简化了数据处理流程
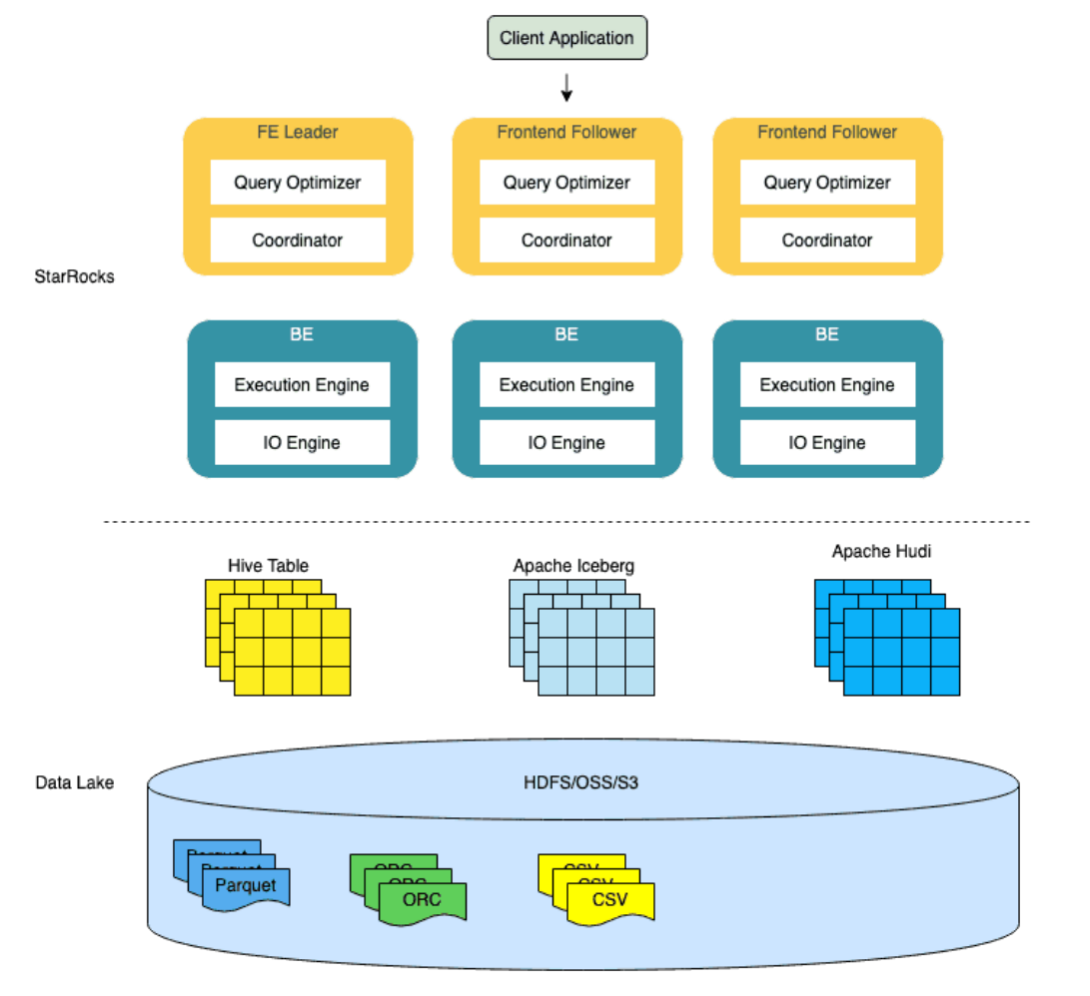
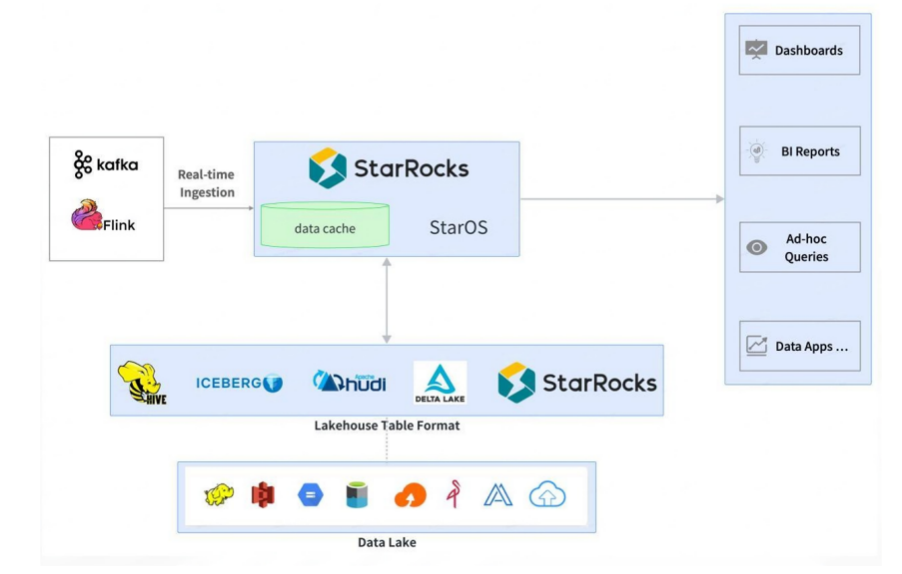
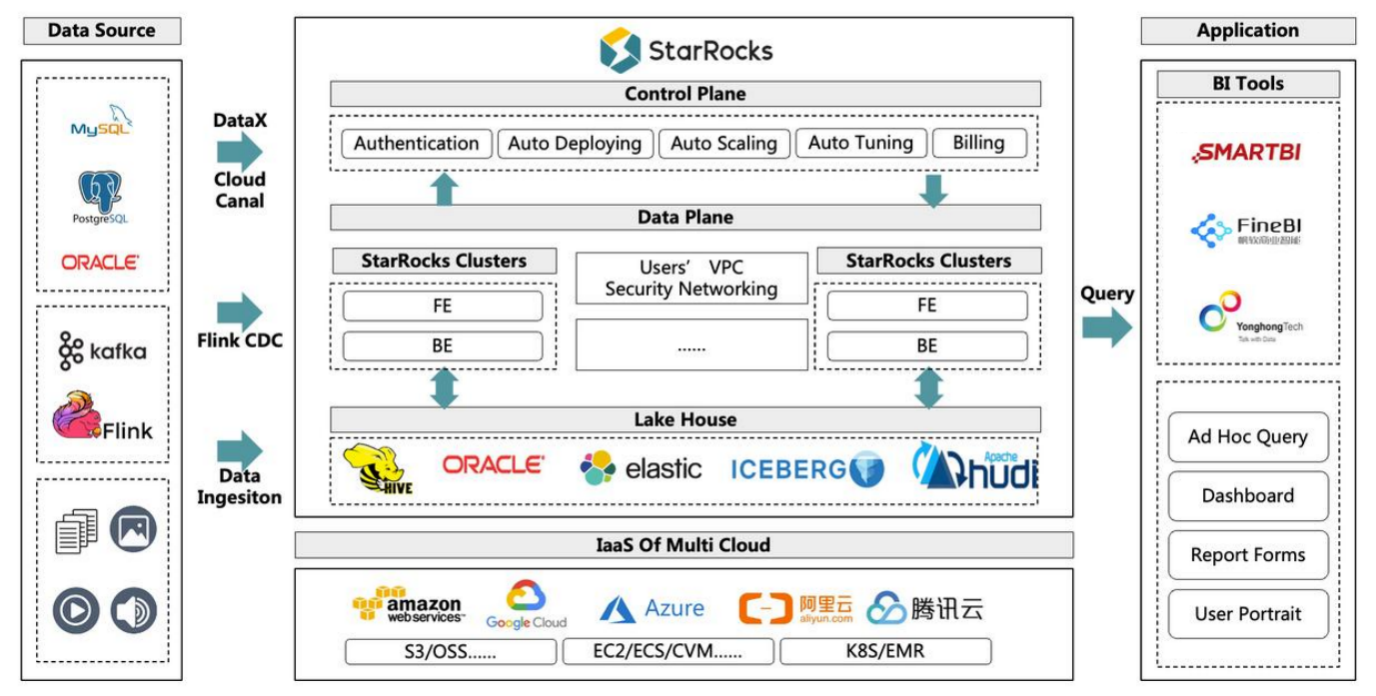
StarRocks 不仅能高效的分析本地存储的数据,也可以作为计算引擎直接分析数据湖中的数据
在数据湖分析场景中,StarRocks 主要负责数据的计算分析,而数据湖则主要负责数据的存储、组织和维护
产品特性

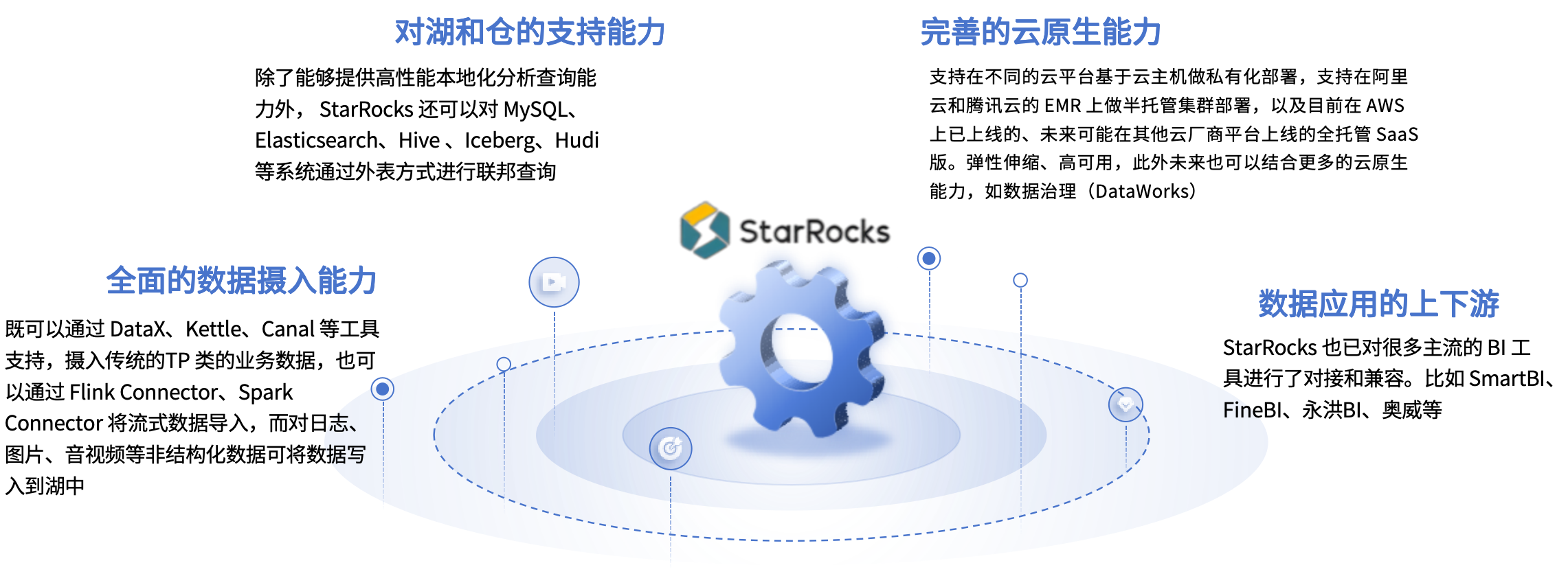
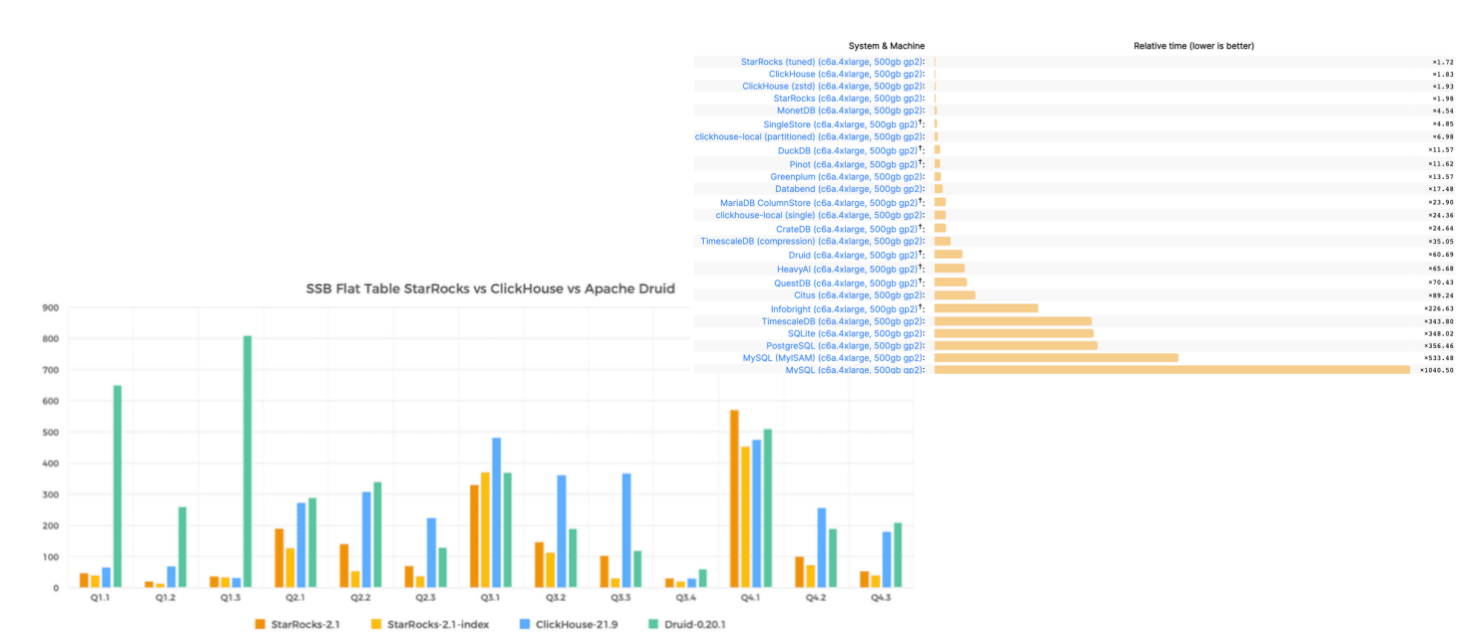
StarRocks极致的性能表现
StarRocks 一直在追求“极致”性能,测试中,StarRocks 的性能是同类型产品的 3 倍到 8 倍

丰富的 Manager 管理功能
灵活的私有化部署
安全稳定,生态完善
在复杂查询、高并发、实时分析等 OLAP 场景下,提升分析效率,实现数据价值的最大化
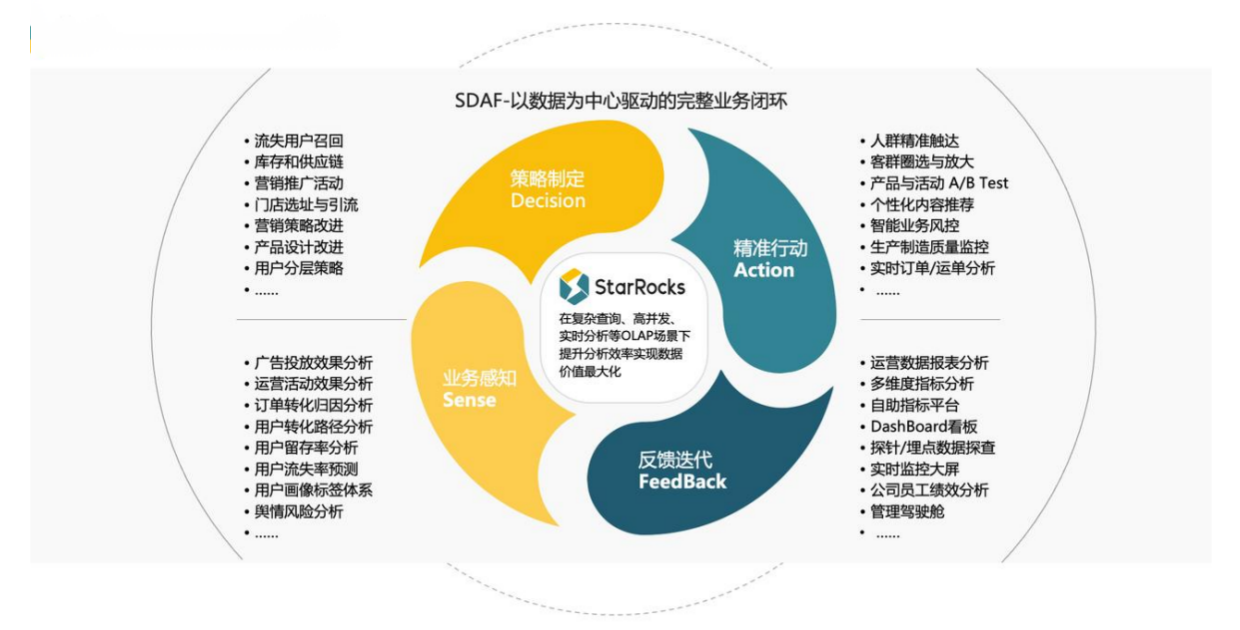
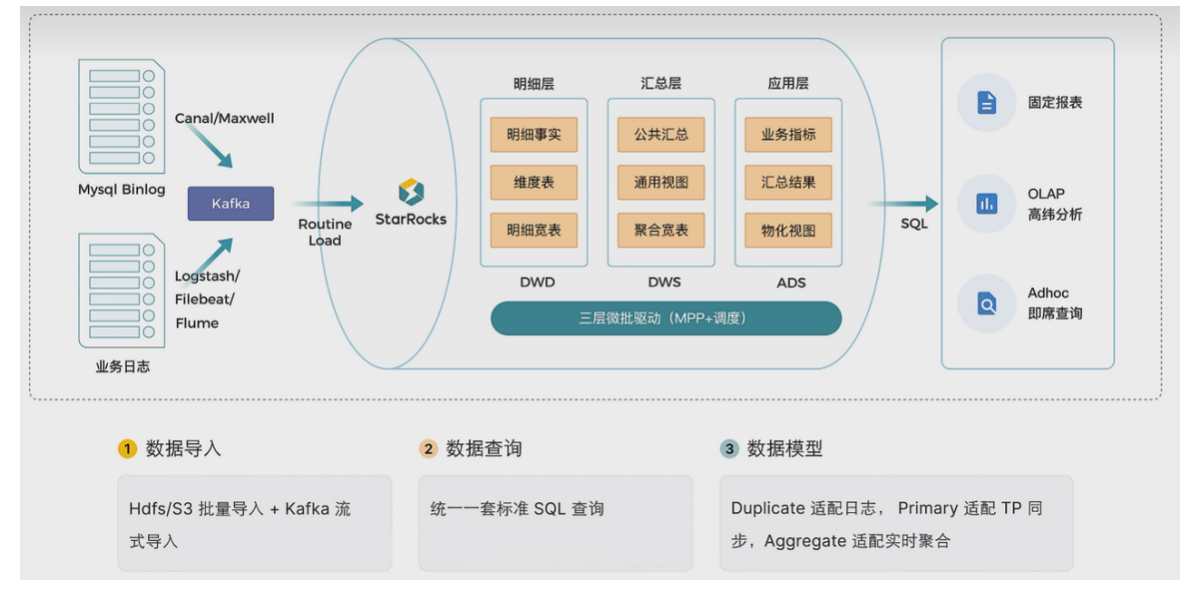
利用 StarRocks 的 MPP 框架和向量化执行引擎,用户可以灵活的选择雪花模型,星型模型,宽表模型或者预聚合模型
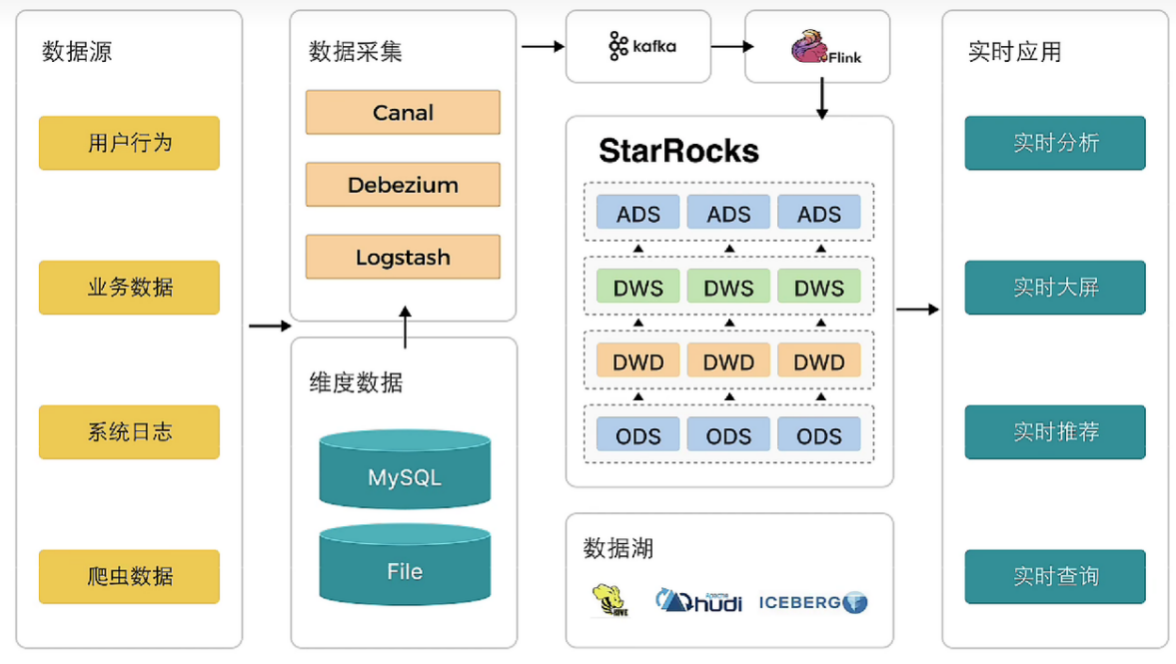
StarRocks 设计和实现了 Primary-Key 模型,能够实时更新数据并极速查询,可以秒级同步 TP (Transaction Processing) 数据库的变化,构建实时数仓
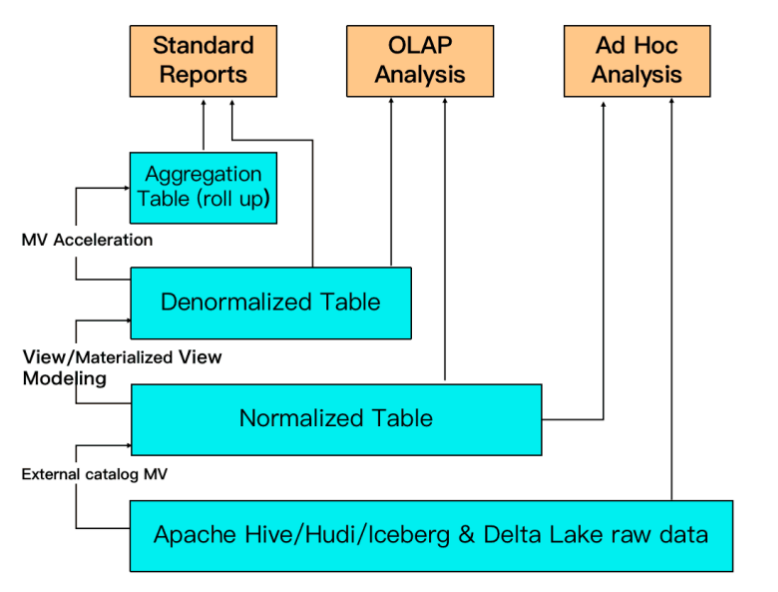
StarRocks 通过良好的数据分布特性,灵活的索引以及物化视图等特性,可以解决面向用户侧的分析场景
一套系统解决多维分析、高并发查询、预计算、实时分析查询等场景,降低系统复杂度和多技术栈开发与维护成本