在数字化时代,企业每天产生海量数据——用户点击、订单交易……这些原始数据本身杂乱无章,若直接用于分析,不仅效率低下,还容易出错。为了让数据真正“可用、可信、可复用”,数据仓库(Data Warehouse)应运而生。而在数据仓库建设中,分层设计是最核心的架构思想之一。

本文将通俗解释:什么是数据仓库分层?为什么它如此重要?以及我们是如何实现它的?
一、 什么是数据仓库分层?
数据仓库分层是指将数据处理流程划分为多个逻辑层级(如贴源层、明细层、汇总层等),每一层承担特定职责,逐层清洗、整合、聚合,最终输出高质量分析数据。这种架构是实现“可用、可信、可复用”数据资产的基础。
二、 数仓分层为什么重要?
很多人误以为分层只是“为了看起来更规范”,实则不然。在缺乏分层的系统中,每个报表都从原始日志临时计算,导致口径不一、性能低下、维护困难。分层通过职责分离与模型沉淀,系统性解决以下关键问题:
市场部定义的“活跃用户”可能是“登录过”,产品部却认为是“有点击行为”。这种歧义会直接误导决策。
分层通过在中间层(如明细层 DWD 或汇总层 DWS)固化指标定义,确保所有上层应用复用同一份逻辑,从根本上消除口径冲突。
若没有统一的明细数据底座,每个新需求都要重复解析用户ID、关联商品信息、处理时间格式——不仅耗时,还极易出错。
分层将通用逻辑下沉至公共层,新报表只需在上层扩展,开发效率显著提升,且变更影响范围可控。
直接在TB级原始日志上跑“月度GMV统计”?响应可能长达数分钟。
通过在汇总层(DWS)预计算聚合结果(如按天/渠道/品类的销售额),上层查询变为高效点查,BI工具可实现秒级响应。
分层天然形成清晰的数据血缘链路(应用层 → 汇总层 → 明细层 → 贴源层)。当报表异常时,可快速定位问题环节;同时,每层可配置独立的质量规则(如非空率、唯一性),实现全链路监控。
无论是引入实时数据、构建AI特征库,还是对接数据湖,分层架构都能平滑扩展。例如,在现有明细层基础上增加实时管道,即可实现“离线+实时”双链路,而无需推翻重来。
三、 如何实现数仓分层?
理解了价值,关键在于落地。我们以一个通用的五层架构(L1–L5)为例,说明如何系统性构建分层体系:
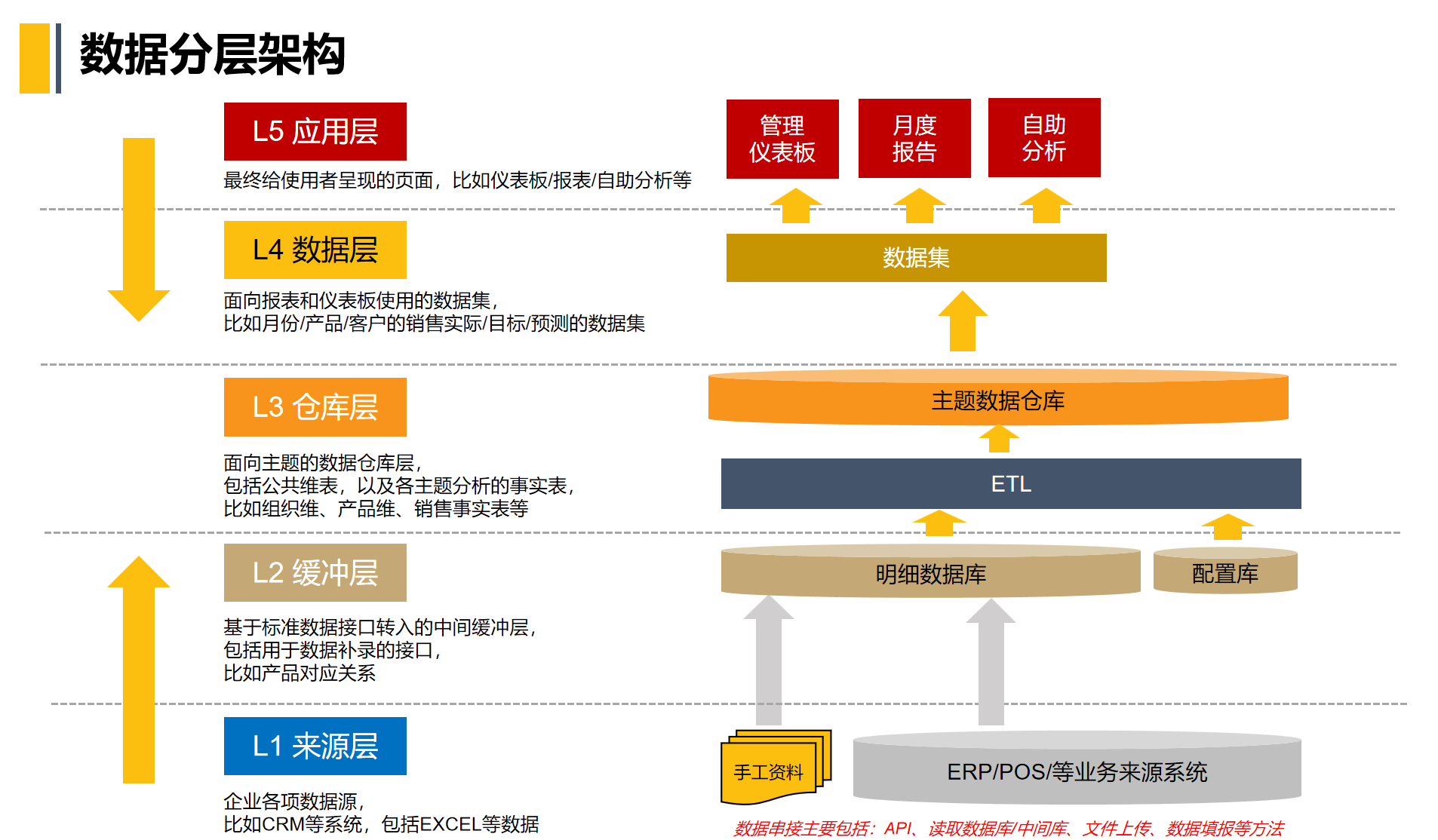
L2:缓冲层(ODS)——保真与隔离
核心目标:原样保留源数据,隔离业务系统与数仓。
示例实践:按天分区存储原始快照;仅做技术性清洗(去重、编码转换),不修改业务语义,便于审计回溯。
L3:仓库层(DWD + DIM)——统一建模的核心
核心目标:构建企业级可信明细数据底座。
示例实践:采用维度建模(星型模型),建立事实表与维度表;标准化字段(如“status: 1 → 成功”);处理缓慢变化维度(SCD Type 2);校验DWD数据质量(如金额 > 0、用户ID非空)。
L4:数据层(DWS)——面向主题的聚合
核心目标:提升分析效率,减少重复计算。
示例实践:按业务域划分主题(用户、商品、渠道);构建宽表(如“用户日行为宽表”整合登录、浏览、下单);聚合粒度明确,指标逻辑与DWD严格对齐。
L5:应用层(ADS)——按需交付
核心目标:直接服务业务场景,无需二次加工。
示例实践:每张表对应明确需求(如“市场ROI日报”);包含复杂派生逻辑(如“7日复购率”);为BI工具、看板或API提供最终数据来源。
四、 结语
数据仓库分层设计,本质上是一种用结构换秩序、用分层换效率的工程智慧。它不追求一步到位,而是通过清晰的职责划分,让数据在流动中不断增值,最终成为企业可信赖的资产。
当你下次看到一张精准、及时、一致的业务报表时,请记住:它的背后,是一套严谨分层架构在默默支撑。

