AI的效能直接取决于数据质量。未治理的数据(孤岛、错误、不统一)将导致AI输出无效甚至有害,形成“垃圾进,垃圾出”。完善的数据治理(整合、清洗、主数据管理)是保障AI精准、可靠、安全的基石。同时,AI也能赋能治理,实现双向增效。
先说答案:在AI时代,数据治理不仅没有过时,其重要性反而被提升到了前所未有的战略高度。 没有数据治理, AI项目可能功亏一篑。
1. 未治理的数据投喂AI,得不出高质量答案
1.1 数据孤岛,导致AI失去了全局视野
在许多企业,市场部、销售部、客服部的数据各自为政,互不相通。市场部的AI看到的是“广告点击”,销售部的AI看到的是“订单金额”,客服部的AI看到的是“投诉工单”。当高层问AI“我们的明星产品A为何近期增长乏力?”时,缺乏全局数据视角的AI,其回答很可能是片面的。它可能告诉你“广告投放减少”,却无法结合销售数据告诉你“新客转化率本就在下滑”,更无法关联客服数据预警“产品近期客诉量激增”。这样的AI,只是一个高级点的“部门秘书”,而非“企业军师”。

1.2 业务系统录入的错误数据,容易误导AI生成错误答案
库管员在VMS中将库存量“100”输成“10000”。这些看似微小的“脏数据”,会被AI会忠实地学习。一个基于错误库存数据训练的智能补货模型,会持续下达错误的采购指令,最终导致库存积压与资金浪费。正所谓“垃圾进,垃圾出”,应用在AI训练上是最恰当的。
1.3主数据不统一,让AI回答与真实情况差之千里
这是最典型、也最致命的问题。例如客户甲,在ERP里叫“甲001”,在CRM里叫“甲1”,在OMS里又成了“甲A”。当CEO问AI:“来自客户甲的年度总收入是多少?”AI会直接“懵掉”——在它的世界里,这是三家不同的公司。主数据(客户、产品、供应商等核心实体)不统一,AI就无法建立正确的关联,它的所有分析和回答,都将建立在扭曲的认知之上,结果必然与真实情况差之千里。
2. 治理后的数据,才能让AI产出高质量答案
2.1 跨业务系统数据整合,让AI能更全面理解企业真实情况
通过数据治理建立企业级数据仓库或数据湖,打破部门墙,将市场、销售、供应链、财务等全域数据按主题进行拉通、整合。这时,再问AI同样的问题,它就能像一位真正的“企业大脑”,综合分析广告曝光、渠道转化、用户复购、供应链成本、客户满意度等多维度信息,给出一个立体、深入的洞察报告,甚至预警潜在风险。全局数据,赋予AI全局智慧。
2.2 清洗剔除掉错误数据,让AI回答更加精准高效
数据治理的核心环节之一,就是通过规则发现、清洗或剔除异常值、重复项和错误数据。当AI以一份“干净”且高质量数据集进行训练和学习时,其产出的模型精度、预测准确性和决策可靠性将大幅提升。

2.3主数据治理,让AI更能理解企业业务
建立统一的主数据管理平台,为客户产品等主要主数据赋予全公司唯一、准确的“身份证”。从此,无论数据来自哪个系统,AI都能准确地将客户甲的所有信息关联起来。这不仅让AI的回答更准确,更让AI真正理解了企业的核心业务实体及其关系,进而为精准的回答奠定扎实的数据基础。
3. AI时代的数据治理特色
AI的浪潮,不仅没有冲垮数据治理,反而为其带来了新的内涵和工具,进入了“双向赋能”的新阶段。
3.1 知识库与数据治理双管齐下,让AI理解企业“黑话”、行业常识
企业内有大量行业术语、部门“黑话”(如医疗企业的植入量和终端)。数据治理定义了数据的“形”(字段、格式),而企业知识库则赋予数据“神”(含义、背景)。例如,治理后数据里有字段“SKU”,知识库则告诉它“SKU-A代表某型号手机,具有5G特性”。将治理后的数据与知识库结合投喂给AI,AI才能理解业务语境,给出更专业的回答,而不会把“SKU”误当成普通编码。

3.2 AI赋能数据治理,提升治理效率
过去,数据治理大量依赖人工,费时费力。现在,AI正成为治理工作的“超级助手”。
智能数据分类与打标:利用自然语言处理(NLP)技术,自动扫描数据内容,识别出敏感数据(如身份证、银行卡号)并进行分类分级。
自动化数据质量探查:机器学习模型可以自动学习数据模式,发现异常值、重复记录,实现7x24小时的质量监控。
智能数据血缘分析:自动解析和可视化数据从产生到消费的完整链路,当某个数据源出问题时,能瞬间定位受影响的所有下游报表和AI模型。
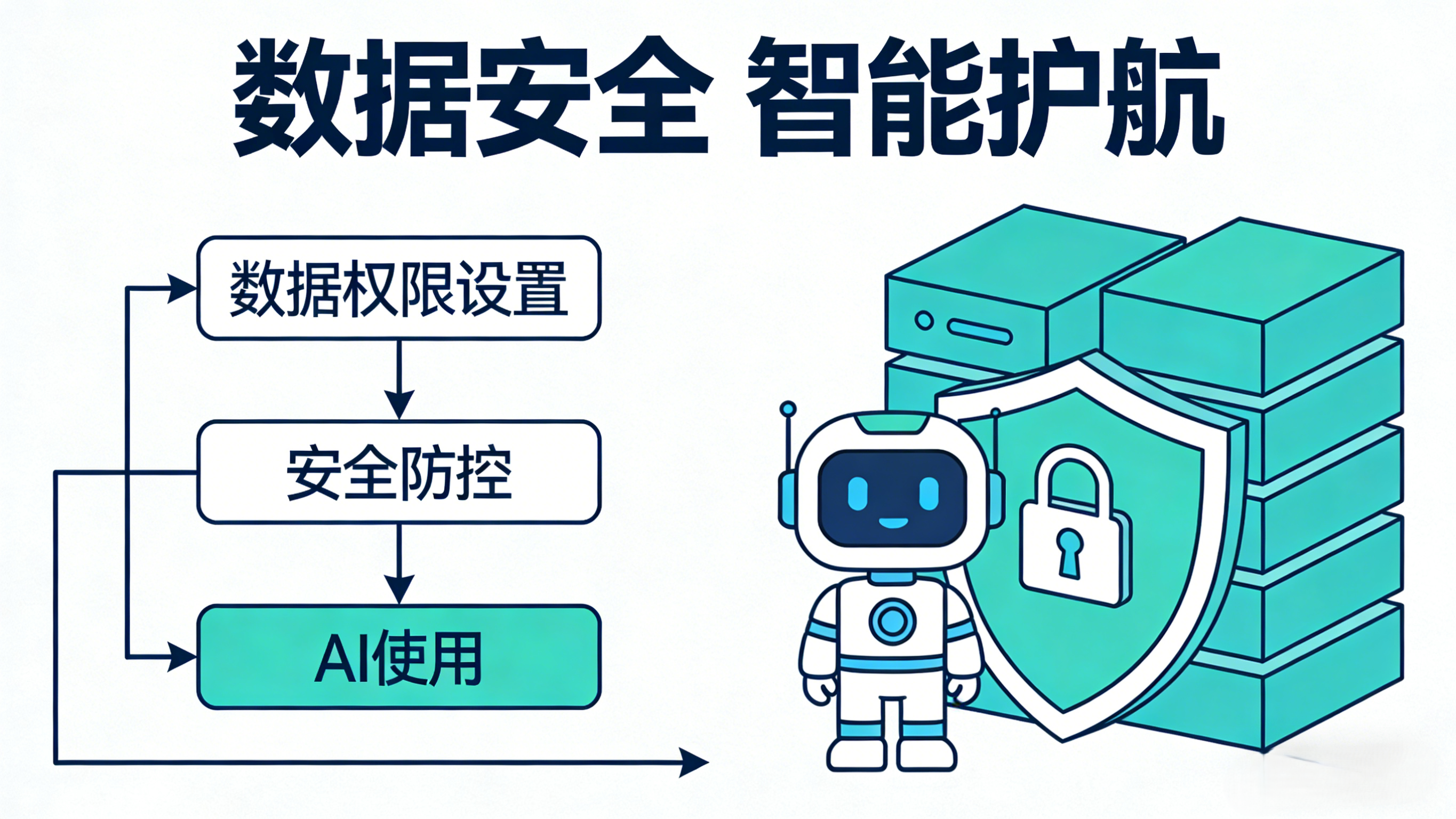
3.3 数据治理过程中做好数据权限等安全防控
数据越是集中、价值越高,风险也越大。在治理之初,就必须将数据安全与隐私保护融入架构。通过严格的数据权限管控、数据脱敏、操作审计等措施,确保在向AI提供数据“燃料”的同时,防止核心数据泄露、滥用。特别是涉及员工与客户个人隐私的数据,必须遵循“最小必要”原则,并做好匿名化处理,这是合规的底线,也是企业的“安全带”。
4. 总结
在AI定义未来的竞赛中,那些能率先构建起高质量、高可信、高安全数据底座的企业,才能真正驾驭AI的力量,赢得未来。
德昂信息十七年来专注于数据管理领域。为企业提供高效、透明、智能的数据解决方案,帮助企业实现数据可信、分析透明以及决策智能。

